Pipeline
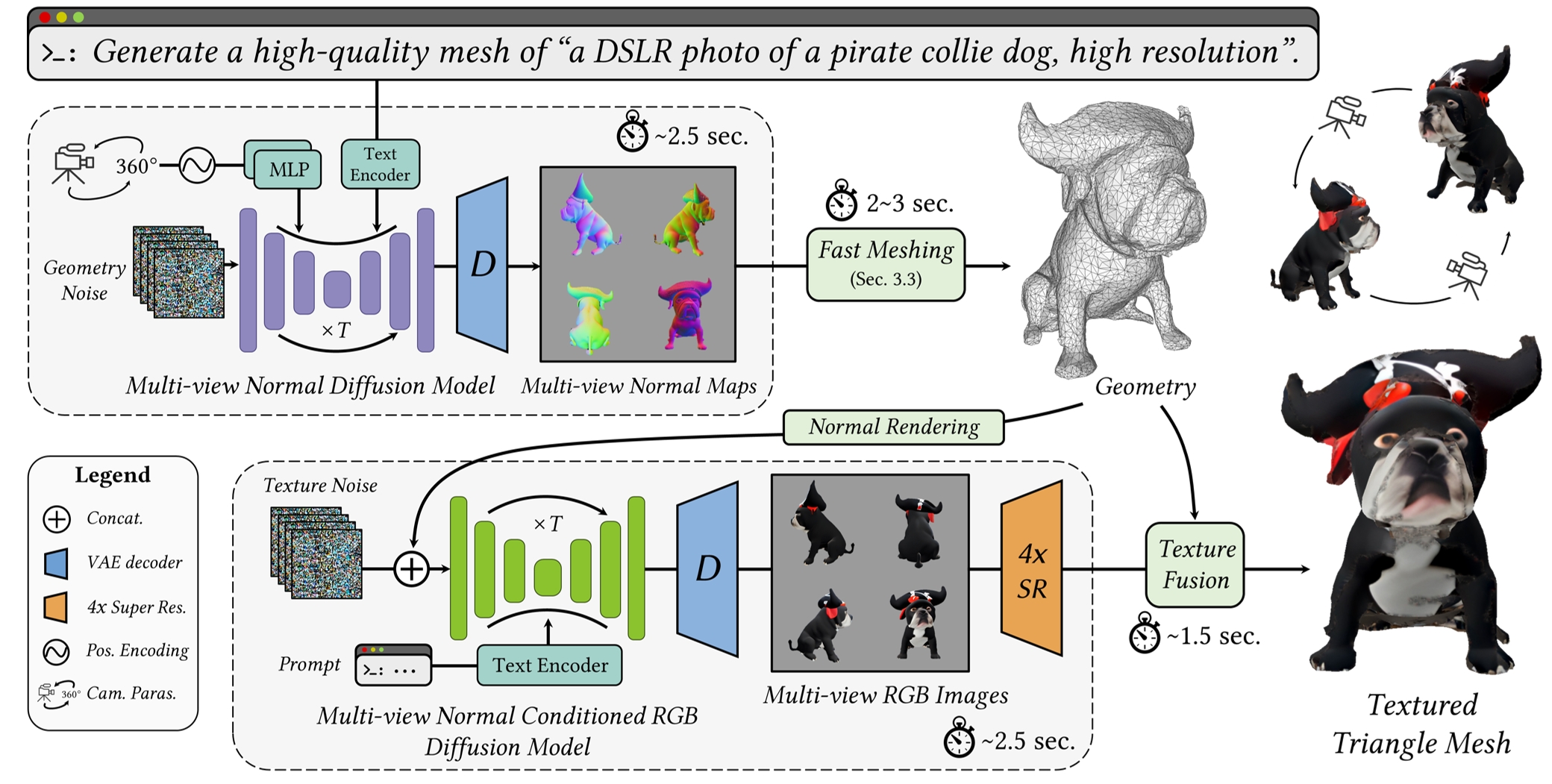
Overview of our text-to-3D content generation system. The generation is a two-stage process, first generating geoemtry and then appearance. Specifically, the system is composed of the following steps: 1) a single denoising process to simultaneously generate 4 normal maps; 2) fast mesh optimization by differentiable rasterization; 3) a single denoising process to generate 4 images conditioned on rendered normal maps; 4) texture construction from multi-view images. The whole generation process only takes 10 seconds.