Video-to-4D
Using STAG4D, you can create high-quality 4D content from a monocular front-view video.
















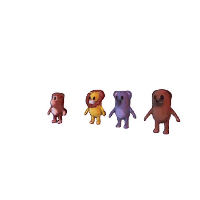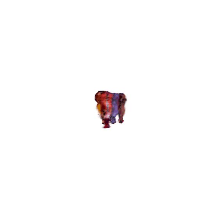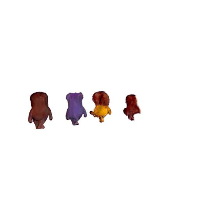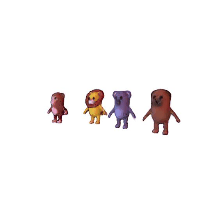
Recent progress in pre-trained diffusion models and 3D generation have spurred interest in 4D content creation. However, achieving high-fidelity 4D generation with spatial-temporal consistency remains a challenge. In this work, we propose STAG4D, a novel framework that combines pre-trained diffusion models with dynamic 3D Gaussian splatting for high-fidelity 4D generation.
Drawing inspiration from 3D generation techniques, we utilize a multi-view diffusion model to initialize multi-view images anchoring on the input video frames, where the video can be either real-world captured or generated by a video diffusion model. To ensure the temporal consistency of the multi-view sequence initialization, we introduce a simple yet effective fusion strategy to leverage the first frame as a temporal anchor in the self-attention computation. With the almost consistent multi-view sequences , we then apply the score distillation sampling to optimize the 4D Gaussian point cloud. The 4D Gaussian spatting is specially crafted for the generation task, where an adaptive densification strategy is proposed to mitigate the unstable Gaussian gradient for robust optimization.
Notably, the proposed pipeline does not require any pre-training or fine-tuning of diffusion networks, offering a more accessible and practical solution for the 4D generation task. Extensive experiments demonstrate that our method outperforms prior 4D generation works in rendering quality, spatial-temporal consistency, and generation robustness, setting a new state-of-the-art for 4D generation from diverse inputs, including text, image, and video.

Using STAG4D, you can create high-quality 4D content from a monocular front-view video.
Our method is designed to be readily adaptable to text and image inputs, offering novel capabilities such as directly generating video sequences from textual descriptions or static images.
Building upon our attention mechanism, we have integrated our design with the newly introduced normal map model by Zero123++. As far as we know, this is the first time that people can generate temporal-coherent multiview images with corresponding normal maps.
Our method also support compose different result together. Building upon this, we could create a scene from a video containing multiple object.
@article{zeng2024stag4d,
title={STAG4D: Spatial-Temporal Anchored Generative 4D Gaussians},
author={Yifei Zeng and Yanqin Jiang and Siyu Zhu and Yuanxun Lu and Youtian Lin and Hao Zhu and Weiming Hu and Xun Cao and Yao Yao},
year={2024}
}